MapReduce
MapReduce
MapReduce 是一种分布式计算模型,它将一个计算任务分解为多个子任务,并使用多个节点来执行这些子任务。MapReduce 的主要优点是它可以处理大型数据集,并自动处理数据分片和合并。
对当时的谷歌来说,这个计算模型最大的好处是可以运行在廉价的集群上面,来进行分布式的计算。
以我本科时候大数据的实验为例,还能在网盘中找到。简单来说就是map和reduce两个函数,map函数将数据会生成多个中间的KV键值对,然后reduce函数将键值对进行合并。可以参考下面的代码。
//context 是mapper任务的上下文
protected void map(Object key, Text value, Context context){
String line = value.toString();
String[] vals = line.split("\t");//以制表符为界
String uid = vals[1];//用户id
String search = vals[2];//搜索关键词
context.write(new Text(uid), new Text(search+"|||"+search.length()));
}
protected void reduce(Text key, Iterable<Text> values, Context context) {
String result = "";
for (Text value : values) {
String strVal = value.toString();
result += (strVal+" ");
}
context.write(new Text(key + "\t"), new Text(result));
}注
尽管前面的伪代码使用字符串作为输入和输出,但从概念上讲,用户提供的 map 和 reduce 函数具有相应的类型:
map(k1, v1) → list(k2, v2)
reduce(k2, list(v2)) → list(v2)map 输出的 value 类型,必须和 reduce 函数接收的 value 类型一样; 但 reduce 最后写出去的 value,可以换成别的类型(比如把 整数 汇总成 字符串 )。
Google 的 MapReduce 系统跑在大量廉价、易坏的普通机器上,用便宜硬盘存数据,靠复制防丢,靠调度器自动分任务,整个系统设计目标是:低成本、高容错、可扩展。
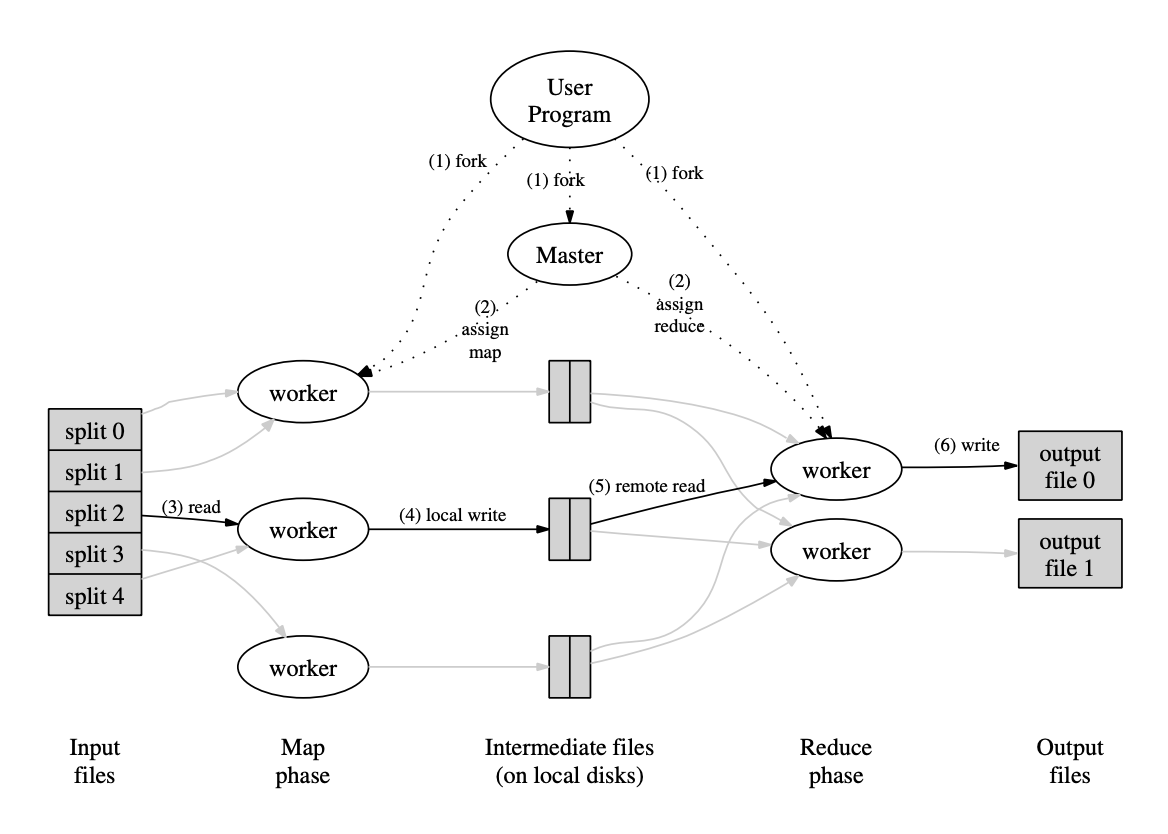
具体的执行过程如下:
- 用户程序启动时,MapReduce 库首先将输入数据划分为若干逻辑分片(通常每片大小为 16–64 MB,可由用户配置),随后在集群中启动多个进程副本以并行执行任务。
- 其中一个副本作为主节点(master),其余作为工作节点(worker)。主控负责任务调度:它将整个作业划分为 M 个 map 任务和 R 个 reduce 任务,并动态分配给空闲的工作节点。
- 被分配 map 任务的工作节点读取对应的输入分片,解析出键值对,并将其传递给用户定义的 map 函数。map 函数生成的中间键值对暂存于内存缓冲区中。
- 当缓冲区达到阈值时,中间结果会按分区函数(partition function)被划分成 R 个区域(对应 R 个 reduce 任务),并批量写入本地磁盘。写入完成后,该节点将这些中间文件的位置信息上报给主控,由主控转发给相应的 reduce 工作节点。
- 各 reduce 工作节点通过远程读取(remote read)从所有完成 map 任务的节点拉取其所属分区的中间数据。数据全部获取后,reduce 节点按中间键进行排序,使得相同键的所有值连续排列;若数据量超出内存容量,则采用外部排序机制。
- 随后,reduce 节点遍历排序后的数据,对每个唯一键及其对应的值列表调用用户提供的 reduce 函数。reduce 的输出结果被追加至最终的输出文件中,每个 reduce 任务生成一个独立的输出文件(共 R 个)。
- 当所有 map 任务和 reduce 任务均执行完毕后,主节点唤醒用户程序。此时,用户代码中调用的 MapReduce 接口返回,控制权重新移交至用户程序的后续逻辑。
容错处理
主节点,记录(idle, in-progress,or completed)这样的数据结构,并且识别集群中有没有坏掉的机器。
工作节点故障
主节点会定期向工作节点发送心跳探测,确保在线。并作为中间数据的调度中枢:每当一个 map 任务完成,主节点便记录其生成的 R 个中间文件分区的位置和大小,并将这些元数据增量推送给正在执行 reduce 任务的工作节点。
已完成的 map 任务在节点故障后需要重新执行,因为其输出结果存储在故障机器的本地磁盘上,无法访问。而已完成的 reduce 任务则无需重试,因为其输出结果存储在全局分布式文件系统中,具有高可用性。
这里注意是成功之后,发生了故障,如果在之前故障,map 或 reduce 都是失败的任务,再重新执行。
主节点故障
主节点可以轻松地定期将其上述数据结构写入检查点(checkpoint)。如果主任务意外终止,系统可从最后一个检查点状态恢复并启动新的主控实例。我记得在当下hadoop的实践中,会有SecondNameNode进行替代,在其他分布式实践中,会重新推举主节点。
数据局部性
GFS 将每个文件划分为 64 MB 的块,并在不同机器上保存每个块的多个副本(通常为 3 副本)。MapReduce 主节点会获取输入文件的副本位置信息。如如果出现故障,主节点会尝试在最近的故障附近副本进行低哦阿杜工作。当在集群中大量工作节点上运行大规模 MapReduce 作业时,绝大多数输入数据可在本地读取,从而无需消耗网络带宽。
任务粒度
我们将 map 阶段划分为 M 个片段,reduce 阶段划分为 R 个片段,如前所述。理想情况下,M 和 R 应远大于工作节点的数量。在实现中,M 和 R 的大小存在实际限制,因为主节点需要做出 O(M + R) 次调度决策,并在内存中维护 O(M × R) 的状态信息(如上所述)。尽管内存使用中的常数因子较小(每对 map/reduce 任务的状态仅需约 1 字节数据),但该开销仍需考虑。谷歌的实际案例,在 2,000 台工作节点上执行 MapReduce 计算,采用 M = 200,000 和 R = 5,000 的配置。
备份任务
MapReduce 会出现严重的尾延迟现象,map或reduce任务出现异常,耗时增加会拖慢整个计算。例如,硬盘存在故障的机器可能会频繁发生可纠正错误,导致其读取性能从 30 MB/s 降至 1 MB/s。集群调度系统可能已在该机器上运行了其他任务,造成 CPU、内存、本地磁盘或网络带宽的竞争,从而减缓 MapReduce 代码的执行速度。我们近期遇到的一个问题是:机器初始化代码中存在一个缺陷,导致处理器缓存被禁用,受影响机器上的计算速度下降超过一百倍。
为缓解拖后腿问题,谷歌设计了一种通用机制:当 MapReduce 操作接近完成时,主节点会为剩余的未完成任务启动备份执行。只要主任务或备份任务中任意一个完成,该任务即被标记为完成。
优化与拓展
分区函数(Partitioning Function)
MapReduce 允许用户指定 reduce 任务数 ( R ),并通过分区函数将中间键分配到对应的 reduce 任务。默认使用 hash(key) mod R 实现均匀负载,但支持自定义分区逻辑(如按 URL 主机哈希),以满足特定数据局部性或输出组织需求。
排序保证(Ordering Guarantees)
系统保证每个 reduce 分区内,中间键值对按键升序处理。这使得每个输出文件天然有序,便于后续高效随机访问或满足应用对结果顺序的要求。
合并函数(Combiner Function)
为减少网络传输开销,MapReduce 支持在 map 端本地执行 combiner(合并函数),对具有相同键的中间结果进行预聚合。combiner 通常复用 reduce 函数逻辑,但仅作用于本地数据,适用于满足交换律与结合律的操作(如求和、计数)。典型应用包括词频统计中大幅压缩 <word, 1> 的传输量。
输入与输出类型(Input and Output Types)
默认文本模式以“偏移量”为键、“行内容”为值;支持按键排序的键值对格式;输入可被合理划分成 map 任务范围(如避免跨行切分);用户可通过实现 reader 接口自定义输入源(如数据库、内存结构)。支持多种输出格式,用户可扩展新类型,便于适配不同下游系统需求。
副作用(side-effects)
MapReduce 允许任务产生额外输出,但要求用户自行保证这些操作的安全性(原子 + 幂等),框架不提供跨文件事务支持。
跳过坏的记录
为应对因用户代码 bug(如第三方库崩溃)导致 MapReduce 任务反复失败的问题,系统提供一种容错执行模式:工作节点通过信号处理器捕获崩溃,并上报出错记录的序列号;主节点识别重复失败的记录后,在后续重试中自动跳过该记录;从而在无法修复代码的情况下,仍能完成对大规模数据集的近似处理。
debug
在集群中debug是非常困难的,因此开发了本地运行的MapReduce库,帮助开发者进行debug。
状态信息(status information)
MapReduce 主节点通过内置 HTTP 服务提供可视化状态页面,实时展示作业进度、资源使用情况和任务执行状态,并提供日志链接与故障信息,使用户能够监控作业运行、预估完成时间、判断是否需扩容,同时在出现异常时快速定位问题根源,显著提升了系统的可观测性与调试效率。
计数样例(Counters Demo)
各工作节点的计数器值会周期性地通过 ping 响应捎带传送到主节点。主节点汇总所有成功执行的 map 和 reduce 任务的计数器值,并在 MapReduce 作业完成后将其返回给用户代码。当前的计数器值也会显示在主控的状态页面上,供用户实时观察计算进度。在聚合过程中,主控会消除相同任务重复执行带来的重复计数,以避免统计偏差(此类重复可能源于备份任务或故障重试)。部分计数器由 MapReduce 库自动维护,例如处理的输入键值对数量和生成的输出键值对数量。用户常利用计数器功能进行合理性校验,例如验证输出对数量是否等于输入对数量,或检查处理的德语文档占比是否在可接受范围内,从而确保作业行为符合预期。
下面是另一个计数的例子
// 自定义计数器(由框架支持)
Counter* error_line_counter;
void map(String key, String value) {
// key: 文档名或偏移量(通常忽略)
// value: 一行文本
// 分词并输出 <word, "1">
vector<String> words = split(value, " ");
for (String word : words) {
EmitIntermediate(word, "1");
}
}
void reduce(String key, Iterator values) {
// key: 单词
// values: 所有 "1" 的列表
int sum = 0;
for (; !values.done(); values.next()) {
sum += StringToInt(values.value());
}
Emit(key, IntToString(sum));
}