语法制导翻译
现在我们来讨论一个整数输入的例子。
解析器可以通过一系列与产生式特定的任务来计算整数值。它可以从左到右累积值,并且每当遇到一个新的数字时,将累积的值乘以十再加上下一个数字。值会与解析中使用的每个符号关联。我们可以将这种策略编码为产生式特定的规则,在解析器进行规约时应用。使用由解析生成器yacc和bison推广的表示法,这些规则可能是:
integer : digit { $$ = $1; }
| integer digit { $$ = $1 * 10 + $2; }这里$$代表整个表达式的值(在左侧),而$1, $2等则代表右侧各符号的值。例如,在规则integer digit中,$1是integer的值,$2是digit的值。当解析器应用这条规则进行规约时,它会执行大括号内的动作来计算新值。
等价树遍历

这些整数语法值计算也可以被写成对语法树的递归遍历。图(a)展示了使用左递归语法的"175"的语法树。图(b)展示了一个简单的树遍历以计算其值。它使用“integer(c)”将单个字符转换为整数值。
树遍历的表述揭示了yacc风格的基于语法的计算的几个重要方面。信息从叶节点向根节点沿着语法树流动。与一个产生式关联的动作仅拥有在该产生式中命名的语法符号所关联的值的名字。自底向上的信息流在这个范式中工作得很好,而自顶向下的信息流则不然。
对自底向上信息流的限制可能看起来有问题。实际上,编译器编写者可以通过在“动作”中使用非局部变量和数据结构来绕过这个范式并规避这些限制。编译器的符号表的一个用途正是提供对通过基于语法的计算得出的数据的非局部访问。
原则上,任何自顶向下的信息流问题都可以通过将所有信息传递给树中的共同祖先并在该点解决问题来用自底向上的框架解决。然而,在实践中,这个想法效果不佳,因为
- 实现者必须规划所有的信息流;
- 她必须编写代码来实现它
- 计算结果出现在树中的一个远离需要它的地方。在实践中,重新思考计算往往比在树周围传递所有这些信息更好。
翻译表达式
下图表示了一个用于构建表达式的抽象语法树的简单语法驱动框架。规则很简单:
- 如果一个产生式包含一个操作符,则它构建一个内部节点来表示该操作符。
- 如果一个产生式推导出一个名称或数字,则它构建一个叶节点并记录词素。
- 如果产生式存在是为了强制优先级,它会将子表达式的抽象语法树(AST)向上传递。
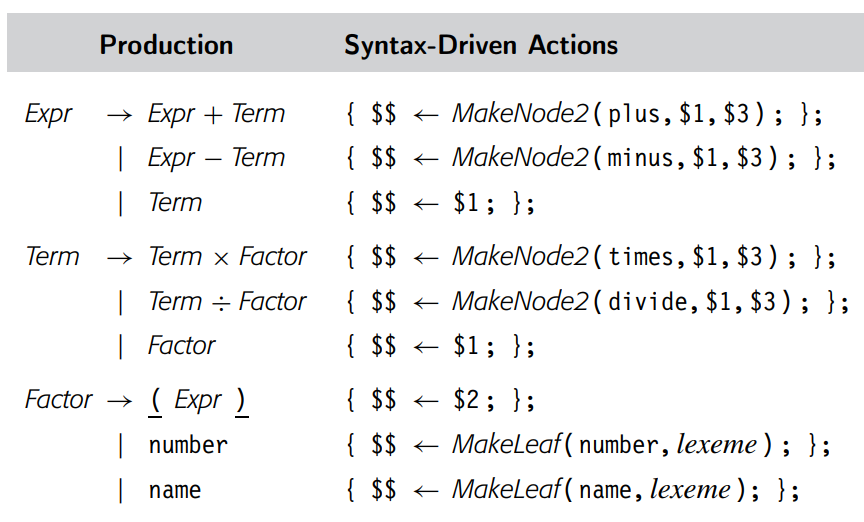
代码使用两个构造函数来构建节点。MakeNode2(a, b, c) 构建一个类型为 a 的二元节点,其子节点为 b 和 c。MakeLeaf(name, a) 构建一个叶节点,并将其与词素 a 关联。对于表达式 a - 2 * b,此翻译方案将构建如边栏所示的简单 AST。
抽象语法树与输入程序的语法结构有直接且明显的关系。三地址码则缺乏这种直接映射。然而,语法驱动框架可以轻松地为表达式和赋值语句发出三地址码。
为了简化框架,编译器编写者提供了高层次的函数以抽象掉值存储位置的细节。
- NextRegister 返回一个新的寄存器编号。
- NumberlntoReg 返回持有来自词素的常量值的寄存器编号。
- STLookup 接受名称作为输入,并返回当前绑定到该名称的实体的符号表条目。
- ValuelntoReg 返回持有来自词素的名称当前值的寄存器编号。

将此语法驱动翻译方案应用于表达式 a - 2 * b 会产生如边栏所示的 ILOC 代码。该代码假定 rarp 持有指向过程本地数据区的指针,且 @a 和 @b 是程序存储 a 和 b 的值相对于 的偏移量。 
处理非本地计算
到目前为止的例子仅展示了语法中的本地计算。单个规则只能命名同一产生式中的符号。编译器的许多任务需要来自计算其他部分的信息;在树遍历表述中,它们需要句法树遥远部分的数据。
编译器中的一个非本地计算示例是将类型、生命周期和可见性信息与命名实体关联起来,如变量、过程、对象或结构布局。编译器在作用域中首次遇到名称时会识别该实体——名称的定义出现位置。在名称x的定义出现位置,编译器必须确定x的属性。在后续引用出现位置,编译器需要访问那些先前已确定的属性。
语法的不同部分将操作符号表表示。名称的定义出现位置创建其符号表条目。如果有声明,它们会设置各种属性和绑定。每次引用出现位置都会查询表以确定名称的属性。打开新作用域的语句,例如过程、块或结构声明,将创建新的作用域并将其链接到搜索路径中。更微妙的问题也可能出现;例如,如果C程序取变量a的地址,如&a,编译器应该标记a为可能存在歧义。
同样的技巧,即使用全局变量在翻译规则之间传递信息,在其他上下文中也会出现。考虑一种源语言,它具有简单的声明语法。解析器可以在处理声明时为每个名称创建符号表条目并记录它们的属性。例如,源语言可能包含类似于以下规则集的语法。
Declaration -> int INameList
| float FNameList
INameList -> NameList name { err ← SetType($2, int); }
| name { err ← SetType($1, int); }
FNameList -> NameList name { err ← SetType($2, float); }
| name { err ← SetType($1, float); }这种形式的语法接受相同的语言。然而,它为 int 和 float 名称创建了不同的名称列表。如上所示,编译器编写者可以使用这些不同的产生式将类型直接编码到语法指导的动作中。这一策略简化了翻译框架,并消除了使用全局变量在产生式之间传递信息的需求。这样的框架更容易编写、理解和维护。有时候,将语法塑造成适应计算的方式可以简化语法驱动的动作。
翻译控制流语句
构建抽象语法树(AST)
解析器可以以一种自然的方式构建一棵抽象语法树来表示控制流构造。考虑使用图5.7中的语法的嵌套if-then-else构造。抽象语法树可以使用一个有三个子节点的节点来表示if语句。一个子节点保存控制表达式;另一个保存then子句中的语句;第三个保存else子句中的语句。边栏中的图显示了对于如下输入的抽象语法树: 如果 e1 则 如果 e2 则 S1 否则 S2 构建这个抽象语法树的动作是直接了当的。 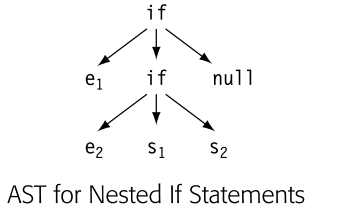
构建三地址码
为了将if-then-else构造翻译成三地址码,编译器必须将控制转移编码为一组标签、分支和跳转。 三地址的中间表示类似于该构造的明显汇编码:
评估控制表达式; 根据情况分支到then子部分(s1)或else子部分(s2); 在选定子部分的末尾,跳转到if-then-else构造之后的语句开始处——即“出口”。 这种翻译方案需要为then部分、else部分和出口设置标签,以及一个分支和两个跳转。 