线性IR
线性IR以有序的操作系列来表示程序。它们是上一节所述的图形IR的替代形式。汇编语言程序是一种线性代码的形式。它由有序的指令序列组成。一条指令可能包含多个操作;如果是这样,这些操作会并行执行。编译器中使用的线性IR通常类似于抽象机器的汇编码。
使用线性形式背后的逻辑很简单。作为编译器输入的源代码是线性的,它生成的目标机代码也是线性的。一些早期的编译器使用了线性IR;对于这些编译器的作者来说,这是一种自然的符号表示法,因为他们以前用汇编语言编程。
线性IR对操作序列施加了全序关系。
如果在编译器中使用的权威IR是线性IR,那么它必须包含一种机制来编码程序各点之间的控制转移。线性IR中的控制流通常模拟目标机上控制流的实现。因此,线性代码通常既包括无条件跳转也包括条件分支。控制流在线性IR中划分了基本块;块在分支处、跳转处或标记操作之前结束。
在大多数指令集架构中,条件分支只使用一个标签。控制流要么流向该标签,这被称为taken branch(取分支),要么流向标签后面的指令,这被称为fall-through branch(直通分支)。直通路径通常比取分支路径更快。
在编译器中,已经使用了许多种类的线性中间表示(IR)。单地址码模拟了累加器机器和栈机器的行为。这些代码揭示了机器对隐式名称的使用,以便编译器可以为此调整代码。由此产生的中间表示可以非常紧凑。双地址码模拟了一种具有破坏性操作的机器。随着破坏性操作和对IR大小的内存限制变得不再那么重要,这类代码逐渐被弃用;三地址码可以显式地模拟破坏性操作。三地址码模拟了一种大多数操作接受两个操作数并产生一个结果的机器。20世纪80年代和90年代RISC架构的兴起使这类代码再次流行起来。
栈机代码
栈机代码是一种单地址码的形式,它假定存在一个操作数栈。它易于生成和理解。大多数操作从栈中读取它们的操作数,并将它们的结果压入栈中。例如,一个减法运算符移除栈顶的两个元素,并将它们的差值压入栈中。 栈的操作规则创建了一些新操作的需求:push操作将一个值从内存复制到栈上,pop操作移除栈顶元素并将其写回内存,而swap操作交换栈顶的两个元素。基于栈的处理器已经被制造出来;这种中间表示似乎是作为那些指令集架构的模型而出现的。表达式 a - 2 × b 的栈机代码出现在边栏中。

栈机代码非常紧凑。栈创建了一个隐式的命名空间,并从中间表示中消除了许多名称,从而缩小了IR的规模。然而,使用栈意味着所有的结果和参数都是临时的,除非代码明确地将它们移至内存。
栈机代码通常用作定义性的中间表示(IR)——经常作为在系统和环境之间传输代码的IR。SMALLTALK-80和JAVA都使用字节码,这是一种基于栈的虚拟机的指令集架构(ISA),作为代码的外部、可解释形式。这种字节码要么在一个解释器中运行,比如JAVA虚拟机,要么在执行前被翻译成目标机器的本地代码。这种设计创造了一个用于分发的程序紧凑形式和一个简单的语言移植到新机器的方案:实现该虚拟机的解释器。
三地址码
在三地址码中,大多数操作具有 i <- j op k 的形式,包含一个操作符(op),两个操作数(j 和 k),以及一个结果(i)。某些操作符,如立即加载和跳转,使用较少的参数。有时,一个操作可能有超过三个地址,例如浮点乘加操作。表达式 a - 2 * b 的三地址码出现在页边。ILOC 是一种三地址码。
三地址码因其几个优点而受到青睐。首先,它相对紧凑。大多数操作由四个部分组成:操作码和三个名称。操作码和名称都来自有限的集合。操作码通常需要一到两个字节。名称通常由整数或表索引表示。其次,操作数和结果的独立命名给予编译器指定和控制名称及值的重用的自由;三地址码没有破坏性操作。三地址码引入了一套新的编译器生成的名称——这些名称保存各种操作的结果。精心选择的命名空间可以揭示改进代码的新机会。最后,由于许多现代处理器实现了三地址操作,因此三地址码很好地模拟了它们的特性。
在三地址码中,支持的操作符集合和抽象级别可以有很大差异。通常,三地址中间表示(IR)会主要包含低级操作,如跳转、分支、加载和存储,以及一些封装控制流的更复杂操作,例如max。直接表示这些复杂操作可以简化分析和优化。
使用三地址码的编译器通常将其部署为确定性的中间表示(IR)。由于具有显式的命名空间和负载-存储内存模型,三地址码特别适合于针对寄存器到寄存器、负载-存储架构的优化。
这里三地址可以参考下一节的LLVM IR 示例。
表示IR
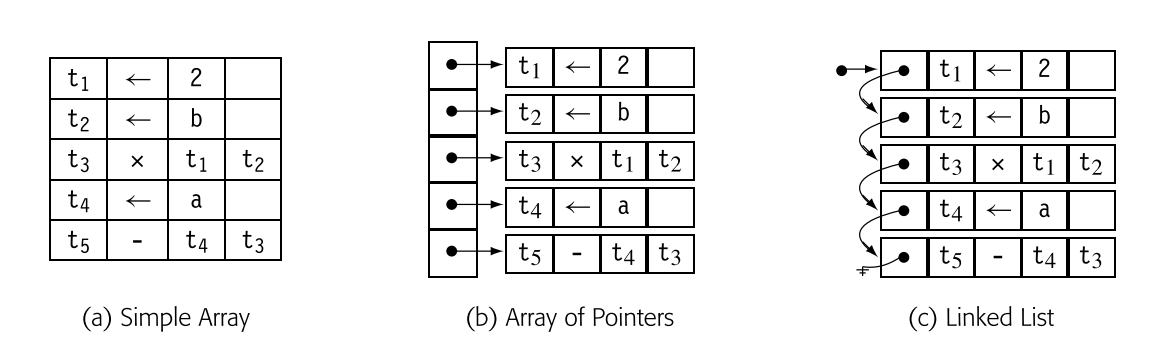
三地址码经常被实现为一组四元组。每个四元组用四个字段表示:一个操作符、两个操作数(或源),以及一个目标。为了形成块,编译器需要一种机制来连接单个四元组。编译器以多种方式实现四元组。  上图展示了三种表示三地址码的方案,对应表达式 a - 2 * b 。第一个方案,在下图(a)中,使用结构体数组。编译器可能会为每个控制流图(CFG)节点构建这样的数组,以保存相应块的代码。在下图(b)中,一个指针向量持有块的四元组。下图(c)将四元组链接成一个列表。
上图展示了三种表示三地址码的方案,对应表达式 a - 2 * b 。第一个方案,在下图(a)中,使用结构体数组。编译器可能会为每个控制流图(CFG)节点构建这样的数组,以保存相应块的代码。在下图(b)中,一个指针向量持有块的四元组。下图(c)将四元组链接成一个列表。
从线性代码构建CFG
CFG的主要特征在于它能够标识每个基本块的起点和终点,并通过边连接这些块,而这些边描述了块之间的可能的控制转移。通常情况下,编译器需要从表示过程的简单线性IR来构建CFG。
构建步骤
基本块识别
- 找到所有基本块的起始位置:
- 程序入口点
- 跳转目标
- 条件分支后的第一条指令
- 每个基本块结束于:
- 跳转指令
- 条件分支指令
- 返回指令
- 找到所有基本块的起始位置:
创建基本块
- 为每个识别出的基本块创建节点
- 将线性代码序列划分为基本块
- 记录每个基本块的起始和结束位置
构建控制流边
- 分析跳转和分支指令
- 添加基本块之间的控制流边:
- 无条件跳转:从当前块到目标块
- 条件分支:从当前块到true和false目标块
- 顺序执行:从当前块到下一个块
优化CFG
- 合并连续基本块
- 消除不可达代码
- 简化控制流结构
示例
考虑以下线性代码:
1: x = 1
2: y = 2
3: if x > y goto 6
4: z = x + y
5: goto 7
6: z = x - y
7: return z构建的CFG如下:
[1-2]
|
v
[3]-----
| \ |
| \ v
v \ [6]
[4-5] /
\ /
v
[7]注意事项
- 正确处理间接跳转
- 处理异常处理的控制流
- 考虑函数调用和返回
- 处理循环结构
- 处理不可达代码