上下文无关语法
上下文无关语法
这一节解析器,主要讨论了如何描述并识别编程语言的语法结构。解析器负责将词法分析器生成的标记流转换为抽象语法树(AST),以便后续的语义分析和代码生成。
解析是编译器前端的第二个阶段。解析器与由扫描器分词后的程序协同工作;它看到的是标注了其语法类别的单词流(类似于它们的词性)。解析器为程序推导出一个句法结构,将单词适配到源编程语言的语法规则模型中。如果解析器确定输入流是一个有效的程序,它会构建程序的具体模型,即中间表示,供编译器的其余部分使用。如果解析器发现错误,它会向用户报告问题及其位置。
首先来探讨一下为什么扫描器中描述的正则表达式不能继续在解析器中使用。
- 正则表达式只能描述有限的语法结构,能表示给定结构的固定次数的重复或者没有指定次数的重复
- 不能用于描述配对或嵌套的结构
- 例如,正则表达式不能描述 语句的语法结构,因为有限自动机无法记录访问他同一状态的次数。
因此在解析器中,我们引入了上下文无关语法,来描述编程语言的语法结构。
上下文无关语法G由一个四元组来进行定义(T,NT,P,S)。
T是终结符的有限集合。语言L(G)中的终端符号集,或称为单词。终端符号对应于扫描器返回的语法类别。NT是非终结符的有限集合。它们是为在G的产生式中提供抽象和结构而引入的语法变量。P是产生式的有限集合。P中的每条规则具有形式 ;也就是说,它用一个或多个语法符号的字符串替换单一的非终端符号。S是开始符号。
上下文无关的的意思在文法推导的每一步
符号串仅根据的产生式推导,而无需依赖的上下文。
提示
上下文语法英文是Context-Free Grammar,简称CFG。注意与后面的CFG,Control Flow Graph区分,控制流图区分。
那么回到上面的例子,如何用一个上下文无关(CFG)语法来描述 :
最左推导和最右推导
最左推导和最右推导很简单,我们用一个例子来进行说明假设有如下的文法规则:
- 最左推导就是始终把最左边的非终结符替换掉。
- 推导过程:
- (最左非终结符A)
- (最左非终结符B)
- (最左非终结符C)
- (推导完成)
- 最右推导就是始终把最右边的非终结符替换掉。
- 推导过程:
- (最右非终结符B)
- (最右非终结符C)
- (最右非终结符A)
- (推导完成)
文法的二义性
文法的二义性是指一个句子可以通过多种不同的方式推导出来,从而产生多个不同的语法树。这种二义性会导致编译器无法确定程序的正确语法结构。
产生二义性的主要原因包括:
- 存在多个产生式可以推导同一个非终结符
- 产生式的顺序安排不当
- 缺少明确的优先级和结合性规则
以if-else语句为例,考虑以下文法:
对于句子 ,则会存在两棵语法推导树。 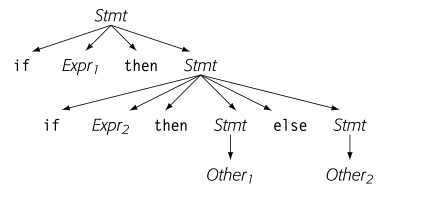
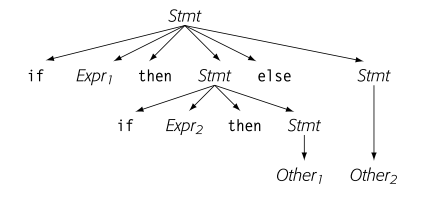
这个语法出现二义性的原因是,每个 与最近的 匹配。 我们可以进行一下修改,就避免产生了二义性: