命名环境建模
当编译器遇到一个名称时,其语法驱动的翻译规则必须将该名称映射到特定实体,如变量、对象或过程。这种名称到实体的绑定在翻译中起着关键作用,因为它确定了名称的类型和访问方法,这反过来又决定了编译器可以生成的代码。编译器使用其对命名空间的模型来决定这个绑定——一个被称为名称解析的过程。
程序的命名空间可以包含多个子空间,或称作用域。根据第4章的定义,作用域是程序中划定命名空间的一个区域。在一个作用域内部,程序员可以定义新的名称。名称在其作用域内可见,并且通常在其作用域外不可见。
用于建模命名环境的主要机制是一组表格,统称为符号表。编译器在初步翻译过程中构建这些表格。对于静态绑定的名称,它用具体的符号表引用注解名称的引用。对于动态绑定的名称,例如C++中的虚函数,它必须做出安排以在运行时解析该绑定。随着解析的进行,编译器会创建、修改并丢弃该模型的部分内容。
在讨论构建和维护可见性模型的机制之前,有必要简要回顾一下作用域规则。
- 静态绑定:当编译器能够在编译时确定名称到实体的绑定,我们认为这种绑定是静态的,即它在运行时不会改变。
- 动态绑定:当编译器无法在编译时确定名称到实体的绑定,而必须将此解析推迟到运行时,我们认为这种绑定是动态的。
词法作用域规则背后的一般原则很简单:
在程序的一个点 p 处,名称 n 的出现指的是在离 p 词法上最近的作用域中创建(明确地或隐含地)的名为 n 的实体。
建模词法作用域
当解析器处理输入代码时,它必须构建并维护命名环境的模型。这个模型随着解析器进入和离开各个作用域而变化。编译器的符号表实例化了该模型。 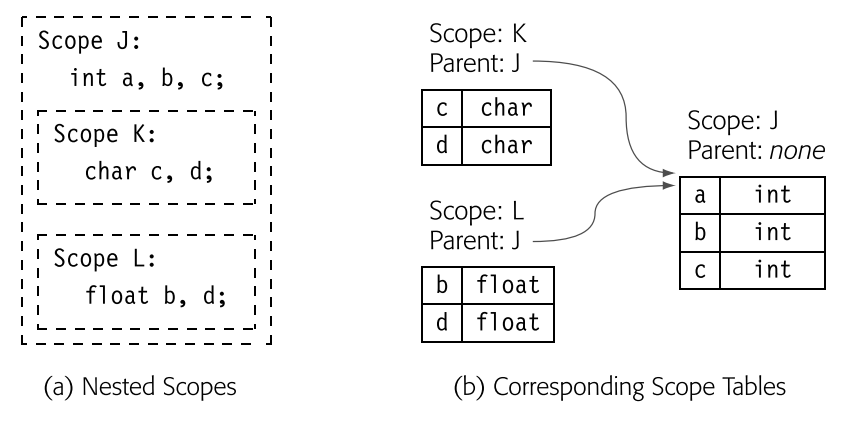
- 块分隔符,如 begin 和 end、f 和 ↓ 以及过程入口和出口,在进入作用域时创建一个新表,并将其链接到与当前作用域关联的块的搜索路径的起始位置。在退出时,应将该表标记为最终状态。
- 变量声明如果存在变量声明,则会在本地表中为声明的名称创建条目并用声明的属性填充它们。如果不存在声明,则必须从引用中推断出诸如类型之类的属性。某些大小信息可能从聚合分配的位置推断出来。 -- 引用会触发沿当前作用域的搜索路径进行查找。在一个有声明的语言中,如果未能在本地表中找到名称,则会搜索整个搜索路径。而在没有声明的语言中,引用可能会创建一个具有该名称的本地实体;它可能指的是周围作用域中的名称。隐式声明的规则是特定于语言的。
建模类的继承结构
为了解析成员名称,编译器需要一个由类声明集定义的继承层次结构的模型。编译器可以在解析某个类的声明时为与每个类关联的作用域构建一个独立的表。源语言中建立继承的语句会使编译器将类作用域链接在一起以形成层次结构。在单一继承的语言中,这个层次结构具有树形结构;类是它们超类的孩子。在一个多重继承的语言中,层次结构形成一个有向无环图。
编译器使用相同的工具来建模继承层次结构和词法层次结构。它创建表格来模拟每个作用域。它将这些表格链接起来创建搜索路径。这些搜索发生的顺序取决于特定语言的作用域和继承规则。而用来创建和维护该模型的基础技术则不然。
编译时解析与运行时解析 某些面向对象语言(OOLs)的主要复杂性并不是来源于继承层次结构的存在,而是这个层次结构在何时被定义。如果OOL要求类定义必须在编译时存在且这些定义不能改变,那么编译器可以解析成员名称、执行适当的类型检查、确定适当的访问方法,并为成员名称引用生成代码。我们说这样的语言具有封闭的类结构。
相比之下,如果语言允许正在运行的程序通过在运行时导入类定义(如JAVA中),或编辑类定义(如SMALLTALK中)来改变其类结构,那么该语言可能需要将一些名称解析和绑定推迟到运行时。我们说这种语言具有开放的类结构。对于开放的类结构,编译器可能需要生成一些代码,使得部分名称解析发生在运行时,就像C++中的虚函数一样。
带有继承的查找设有一个封闭的类结构。考虑两个不同的场景:
- 如果编译器在某个过程p中找到对未限定名称n的引用,它会在词法层次结构中搜索n。如果p是定义在某个类c中的方法,那么n也可能是c的数据成员或是c的某个超类的数据成员;因此,编译器必须将继承层次结构的一部分插入到搜索路径的适当位置。
- 如果编译器找到了对象o的成员m的引用,它首先在词法层次结构中解析o为某个类c的一个实例。接下来,它在类c的表中搜索m;如果搜索失败,则沿c的超类链(按顺序)在每个表中查找m。它要么找到m,要么穷尽了层次结构。
构建模型,当解析器处理类定义时,它可以(1)将类名输入到当前的词法作用域,并(2)为在类中定义的名称创建一个新的表。由于类的内容及其继承上下文都是通过语法指定的,编译器编写者可以使用由语法驱动的动作来构建和填充表格,并将其链接到周围的继承层次结构中。成员名称可以在继承层次结构中找到;未限定名称则可以在词法层次结构中找到。
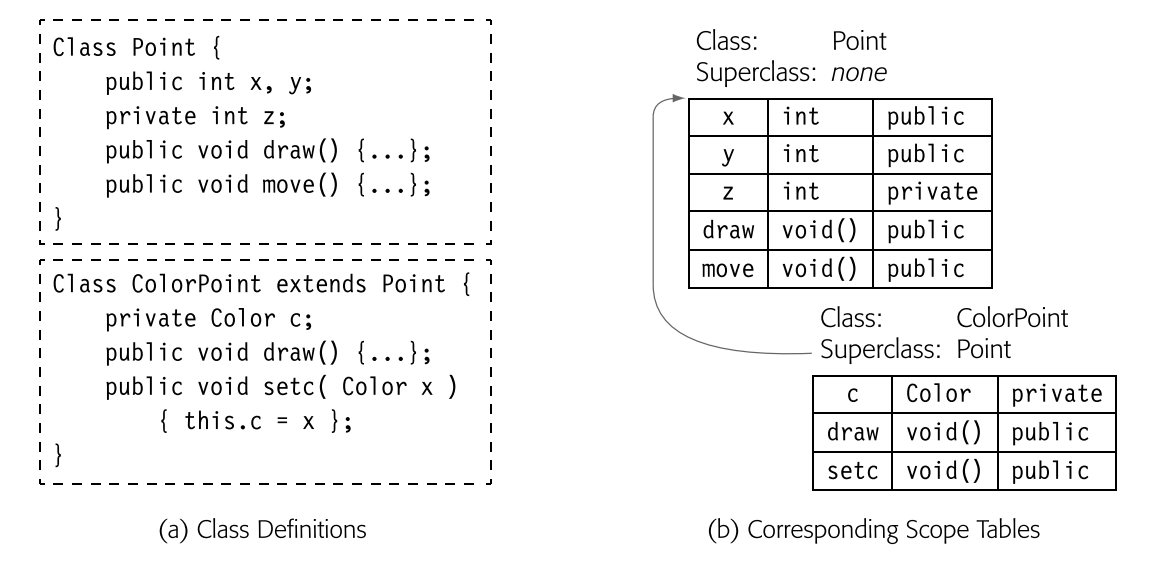
编译器可以使用为词法层次结构设计的符号表构建块来表示继承层次结构。图展示了两个类定义,一个针对Point,另一个是ColorPoint,它是Point的一个子类。编译器可以将这些表链接成一个继承层次结构的搜索路径,在图中表现为一个SuperClass指针。更复杂的情况,比如词法嵌套的类定义,只会产生更复杂的搜索路径。
以及为了支持多重继承,编译器需要一个更复杂的继承层次结构模型。然而,它可以从相同的构建模块:符号表和显式的搜索路径来构建适当的模型。复杂性主要体现在搜索路径上。
接着来讨论类的继承性的可见性。
- public(公共): 成员可以被任何其他类访问。 在继承的情况下,公有成员对子类也是可见且可访问的。
- protected(受保护的): 成员只能在定义它们的类内部、该类的子类以及同一个包内的其他类中访问。 在继承的情况下,受保护成员对子类是可见且可访问的,即使子类不在同一个包内。
- private(私有的): 成员只能在定义它们的类内部访问。 在继承的情况下,私有成员对子类不可见也不可访问。
- 默认(包级私有,无关键字): 如果成员没有指定访问控制修饰符,则它们具有默认的可见性,这意味着它们只能在同一个包内访问。 在继承的情况下,如果子类也在同一个包内,那么它可以看到并访问这些成员;但如果子类在不同的包内,则不能访问。
在翻译期间,编译器经常将名称的词素映射到特定实体,如变量、对象或过程。为了确定名称的身份,编译器使用它构建的表示词法和继承层次结构的符号表。语言规则规定了通过这些表的搜索路径。编译器从搜索路径的最内层级别开始。它对路径中的每个表执行查找,直到找到名称或是在最外层表中查找失败为止。 路径的具体细节取决于语言。如果名称的语法表明它是一个对象相对引用,那么编译器可以从对象类的表开始,并沿继承层次结构向上工作。如果名称的语法表明它是一个“普通”的程序变量,那么编译器可以从引用出现的作用域的表开始,并沿词法层次结构向上工作。如果语言的语法无法区分对象的数据成员和普通变量,那么编译器必须构建一些混合搜索路径,以结合表的方式模拟语言指定的作用域规则。
编程语言提供了控制名称的生命周期和可见性的机制。声明允许显式指定名称的属性。声明在代码中的位置根据语言的作用域规则直接影响到生命周期和可见性。在一个面向对象的语言中,继承环境也会影响命名实体的属性。
为了建模这些复杂的命名环境,编译器使用两个基本工具:符号表和以层级方式链接表的搜索路径。编译器可以使用这些工具来构建上下文特定的搜索空间,以模拟源语言的规则。