符号表
一个或多个数据结构的集合,用于保存有关名称和值的信息。 大多数编译器将符号表作为持久化的辅助数据结构来维护,这些符号表与表示可执行代码的中间表示(IR)一起使用。
在解析期间,编译器会发现许多不同实体的名称和属性,包括命名值,如变量、数组、记录、结构、字符串和对象;类定义;常量;代码中的标签;以及编译器生成的临时值(详见第192页的题外话)。 对于程序中实际使用的每个名称,编译器需要各种信息才能生成操作该实体的代码。具体信息将根据实体的类型而变化。对于简单的标量变量,编译器可能需要数据类型、大小和存储位置。对于函数,则可能需要每个参数的类型和大小、返回值的类型和大小,以及函数入口点的可重定位汇编语言标签。
概念上,符号表有两个主要组成部分:从文本名称到仓库中索引的映射,以及该索引指向名称属性的仓库。这种表的抽象视图如下所示。
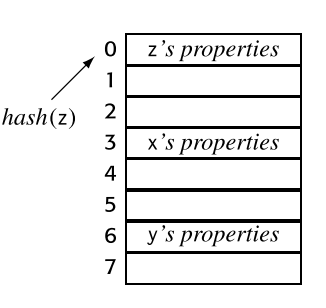 用哈希映射来避免逐个扫描带来的开销。
用哈希映射来避免逐个扫描带来的开销。
符号表的主要作用是解析名称。如果编译器在程序的某个位置p发现了一个对名称n的引用,它需要一种机制将n映射回其在p处有效的命名环境中所做的声明。从名称到声明及其属性的映射必须明确定义;否则,程序可能会有多种含义。因此,编程语言引入了规则来规定名称的特定声明在何处既有效又可见。
通常,作用域是一组连续的语句,在其中名称被声明、可见且可访问。作用域的界限由语言中的特定符号标记。通常,一个新的过程定义了一个覆盖其整个定义的新作用域。C和C++使用大括号来划分代码块。每个代码块定义一个新的作用域。
在大多数语言中,作用域可以嵌套。内部作用域中x的声明会遮蔽周围作用域中任何x的定义。嵌套创建了命名空间的层次结构。这些层次结构在软件中扮演着关键角色
两种最常见的命名空间层次结构是由词法作用域规则和继承规则创建的。编译器必须构建表来模拟每个这样的层次结构。
一个编译器将包含多个不同的表,从符号表和继承表到结构布局表和常量表。对于每个表,编译器设计者必须选择一个合适的实现策略:既包括映射函数也包括存储库。虽然这些选择在很大程度上是独立的,但编译器设计者可能希望在多个表中使用相同的基本策略,以便它们可以共享实现。
映射的实现从文本名称到索引的映射可以通过多种方式进行实现,每种方式都有其自身的优缺点。
线性列表,线性列表构造、扩展和搜索都很简单。线性列表的主要缺点是每次查找所需的时间为 O(n),其中 n 是列表中的项目数量。然而,对于一个小的过程,线性列表可能是有意义的。
树实现,树结构具有列表的优点,包括简单且高效的扩展。它还有潜力显著减少每次查找所需的时间。假设树大致平衡——即每一层的子树大小大致相等——那么每项查找的预期时间应接近 O(log2 n),其中 n 是树中的项目数量。平衡树使用更复杂的插入和删除协议以维持大致相等大小的子树。有许多有效且高效的构建平衡树的技术。不平衡的树具有更简单的插入和删除协议,但不对兄弟子树的相对大小提供任何保证。当面对不利的输入时,不平衡的树可能会退化成线性搜索。
哈希映射(Hash Map) 编译器可以使用一种称为哈希的数值计算,从字符串生成一个整数。一个设计良好的哈希函数h,会分配这些整数,使得很少有字符串会产生相同的哈希值。为了构建哈希表,程序员使用字符串的哈希值对表大小取模的结果作为进入表的索引。
处理冲突是哈希表设计中的一个关键问题,如附录B.4中所讨论的。如果键集不产生冲突,那么在哈希表中的插入和查找应该花费O(1)的时间。如果所有的键都映射到相同的表索引上,那么插入和查找可能会退化为每次查找O(n)的时间,其中n是键的数量。为了避免这个问题,编译器编写者应当使用一个设计良好的哈希函数,这种函数可以在好的算法教科书中找到。静态映射(Static Map) 作为哈希的一种替代方案,编译器可以预先计算一个无冲突的静态映射,将键映射到索引。多重集判别解决了这个问题
对于小规模的键集,一种将键视为一组非循环正则表达式并逐步建立DFA以识别该集合的方法,可以实现快速的执行。一旦转换表的大小超过了第一级数据缓存的大小,这种方法就会显著变慢。
多重判别集
符号表通常使用哈希映射来实现,这是因为哈希的预期效率较高。如果编译器编写者担心哈希可能出现的最坏情况(尽管可能性不大但确实存在),多重集判别提供了一种有趣的替代方案。它通过在扫描器中离线构建索引来避免最坏情况的发生。
为了使用多重集判别,编译器首先扫描整个程序,并为每个标识符实例构建一个 (name, pos) 元组,其中 name 是标识符的词素,pos 是其在分类单词或标记列表中的序数位置。它将所有元组输入到一个大集合中。
接下来,编译器对集合进行字典排序。实际上,这为每个标识符创建了一系列子集。每个子集保存其标识符的所有出现的元组。由于每个元组通过其位置值指向特定的标记,编译器可以使用已排序的集合来修改标记流。编译器对集合进行线性扫描并处理每个子集。它为每个唯一的标识符分配一个符号表索引,然后重写标记以包含该索引。解析器可以直接从标记读取符号表索引。如果编译器需要文本查找功能,生成的表格会按字母顺序排列以便进行二分查找。
这种技术增加了编译的一些成本。它会对标记流进行额外的一次遍历以及字典排序。作为回报,它完全避免了哈希可能带来的最坏情况,并且在解析开始之前就明确了符号表的初始大小。这种技术几乎可以在任何允许离线解决方案的应用中取代哈希表。