实用主题
本节介绍书中所描述的一些解析器的实用性主题。
错误恢复
无论之前的自顶向下还是自低向上的解析器,都有一个共同的问题:它们无法处理语法错误。例如,在自顶向下的解析器中,如果遇到了一个语法错误,它们报告问题并停止。这种行为防止编译器在一个不正确的程序上浪费更多时间。然而,它也确保了编译器每次编译最多只能找到一个语法错误。使用这样的编译器找到代码文件中的所有语法错误可能是一个漫长且痛苦的过程。
一个解析器应该在每次编译中找到尽可能多的语法错误。 解析器需要一种可以从错误中“恢复”的机制,也就是说,转移到一个可以继续进行解析的状态。 实现这一目标的常见方法是选择一个或多个词,解析器可以使用这些词来使输入与其内部状态同步。 当解析器遇到错误时,它会丢弃输入符号,直到找到一个同步词,然后将其内部状态重置为与识别该词一致的状态。
在一个递归下降解析器中,代码可以直接丢弃词直到它找到一个分号。在这一点上,它可以将控制返回到解析语句的例程报告成功的那个点。这可能涉及到操作运行时堆栈或使用类似C语言中的setjmp和longjmp的非本地跳转。 在一个LR(1)解析器中,这种重新同步更加复杂。解析器会丢弃输入直到它找到一个分号。然后,它向后扫描解析堆栈,直到找到一个状态s,使得Goto[s, Stmt]是一个有效的、非错误入口。堆栈上的第一个这样的状态代表包含错误的语句。错误恢复例程随后会丢弃堆栈上的条目直至该状态,并将由Goto[s, Stmt]给出的状态推入堆栈,然后继续正常的解析过程。 在一个表驱动的解析器中,无论是LL(1)还是LR(1),编译器编写者需要一种方法来告诉解析器生成器在哪里进行同步。这可以通过使用错误产生式——即右侧包含指示错误同步点的保留字和一个或多个同步令牌的产生式来实现。有了这样的构造,解析器生成器就可以实现预期的行为。 当然,编译器不应该尝试为语法上无效的程序生成和优化代码。这需要错误恢复装置与调用编译器各个遍历的驱动程序之间进行简单的握手,以便在解析不成功后停止。
一元运算符
经典的表达式语法仅包含二元运算符。然而,代数符号还包括一元运算符,如一元减(负号)和绝对值。其他一元运算符出现在编程语言中,包括自增、自减、取地址、解引用、布尔取反以及类型转换。将这样的运算符添加到表达式语法中需要谨慎处理。
考虑向经典的表达式语法中添加一个一元绝对值运算符,记为||。绝对值的优先级应该比加法或乘法高。但是,它需要比因子(Factor)的优先级低,以确保在应用||之前先计算括号内的表达式。一种书写此语法的方法如图所示。通过这些添加,语法仍然是LR(1)。它允许程序员对任何因子取绝对值。
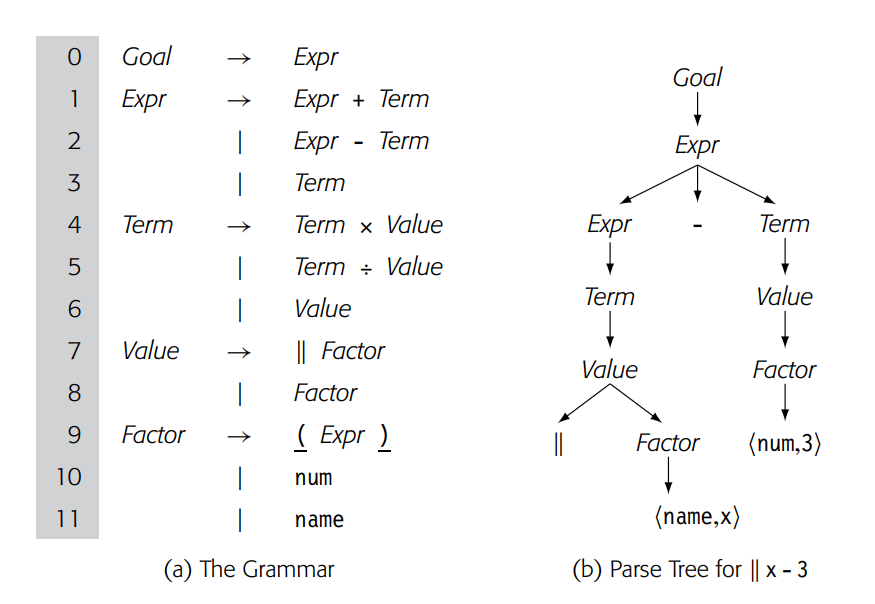
图(b)展示了字符串 || x - 3 的语法树。它正确地显示了代码必须先评估 || x 然后才能执行减法操作。该语法规则防止程序员书写 || || x,因为这在数学上几乎没有意义。然而,它允许 || (|| x),这与 || || x 一样缺乏实际意义。
无法书写 || || x 几乎不会限制语言的表达能力。然而,对于其他一元运算符,问题似乎更为严重。例如,C语言程序员可能需要书写 **p 来对声明为 char **p; 的变量进行解引用。我们也可以为Value添加一个解引用产生式:Value -> * Value。即使我们将项 Term -> Term x Value 中的 x 运算符替换为 *,从而像C语言那样重载运算符 "*",所产生的语法仍然是LR(1)语法。同样的方法也适用于一元减(负号)。
处理上下文相关的歧义
使用一个词来表示两种不同的含义可以造成语法歧义。这个问题的一个例子出现在几种早期的编程语言中,包括FORTRAN、PL/I和ADA。这些语言使用括号来包含数组引用的下标表达式和子程序或函数的参数列表。给出一个文本引用,如fee(i, j),语法上有两种推导:一种是作为二维数组,另一种是作为过程调用。区分这两种情况需要了解fee声明的类型——这是语法上不明显的信息。扫描器无疑在这两种情况下都会将fee分类为一个名称。

由于规则14和15扩展到相同的右部,因此该语法是有歧义的的。LR(1)表构建器将会报告这两个产生式之间的归约-归约冲突。
现在我们看到使用不同的括号来区分下标和调用也将解决这种歧义。()和[]。
解决这种歧义性需要额外的语义知识。在自上而下、递归下降的解析器中,编译器编写者可以将下标(Subscript)和调用(Call)的代码合并,并添加所需的额外代码来检查名称的声明类型。而在使用解析器生成工具构建的表格驱动解析器中,解决方案必须在工具提供的框架内工作。
为了解决这个问题,已经采用了两种不同的方法。编译器编写者可以将函数调用和数组引用都合并到一个产生式规则中。该方案会将问题推迟到后续的翻译阶段,在那时可以通过从声明派生出的类型信息来解决。解析器必须构造一种表示方式,以保留任一解决方案所需的所有信息;某些后续步骤将会根据情况将引用重写为数组引用或函数调用。
另一种选择是,扫描器可以根据它们的声明类型而非微观语法对标识符进行分类。这个方案要求扫描器和解析器之间有协调;只要语言有一个定义前使用的规则,就很容易安排。声明是在使用发生之前被解析的。解析器可以提供其内部符号表给扫描器访问,以将标识符解析为不同的类别,比如变量名和函数名。这些类别随后会在语法中作为不同的非终结符号出现。相关的产生式规则变为:

以这种方式重写后,语法是明确的。扫描器在每种情况下返回一个独特的语法类别,解析器可以区分它们。当然,语言设计者可以避免这种歧义。像C和BCPL这样的语言使用不同的语法来表示函数调用和数组元素引用,这消除了歧义。
总结
错误定位、错误信息和错误恢复对于编译器用户的体验至关重要。编译器编写者需要确保编译器能够发现尽可能多的错误,并且尽可能清晰地报告这些错误的原因。 一元运算符和含糊的结构会给编程语言语法带来复杂性。编译器编写者可以通过调整语法规则、改变解析器-扫描器的交互,或者同时采用这两种方法来处理这些问题。