IR分类
IR的结构组织
大致来说,IR可以分为三类:
- 图形化IR将编译器的知识编码成图。然后算法在节点和边上进行操作。第三章中用来描绘推导的解析树是图形化IR的一个实例,下图中的(a)和(c)图所示的树也是。
- 线性IR类似于某些抽象机器的伪代码。算法迭代简单、线性的操作序列。本书使用的ILOC代码是一种线性IR的形式,下图中的(b)和(d)图所示的表示形式也是。
- 混合IR结合了图形化和线性IR的元素,以捕捉它们的优点并避免它们的缺点。一个典型的控制流图(CFG)使用线性IR来表示代码块,并使用图来表示这些块之间的控制流。
 树形结构的IR自然而然地引导人们以某种形式的树遍历来组织遍次。同样地,线性IR则引导人们以顺序迭代操作的方式来自然地组织遍次。
树形结构的IR自然而然地引导人们以某种形式的树遍历来组织遍次。同样地,线性IR则引导人们以顺序迭代操作的方式来自然地组织遍次。
IR的抽象级别
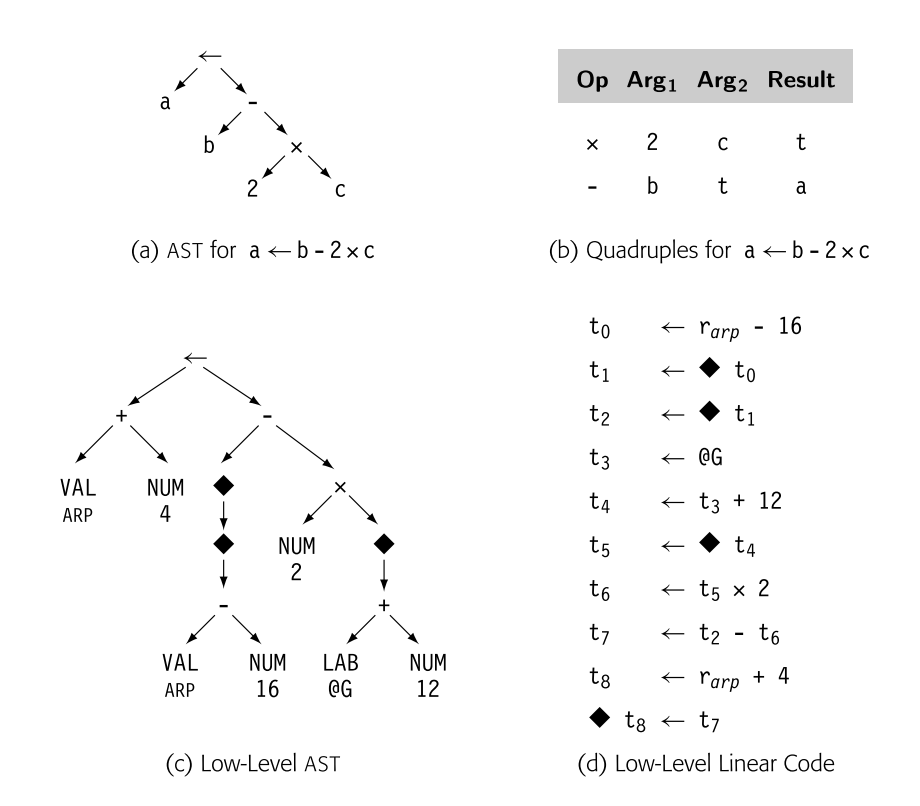
抽象层次与结构无关。上图图展示了语句 a <- b - 2 * c 的四种不同表示方法。(a)和(c)显示了接近源代码级别和接近机器级别的抽象语法树(AST)。(b)和(d)显示了相应的线性表示。
(c)中的低级AST使用表示汇编级别概念的节点。一个VAL节点表示已经位于寄存器中的值。一个NUM节点表示可以放入操作立即数字段的已知常量。一个LAB节点表示汇编级别的标签。解除引用运算符(图中黑色菱形块),将值视为地址并表示内存引用。在黑色菱形块操作符的左边,它表示存储(store)。在黑色菱形块操作符的右边,它表示加载(load)。
抽象层次很重要,因为编译器通常只能优化中间表示(IR)所暴露的细节。在IR中隐含的事实很难改变,因为编译器以统一的方式处理隐含知识,这不利于特定上下文的定制。例如,要优化数组引用的代码,编译器必须重写引用的IR。如果该引用的细节是隐含的,编译器就无法更改它们。
IR使用模式
确定性IR 确定性IR是被编译代码的主要表示形式。编译器不会回溯到源代码;相反,它会分析、转换和翻译代码的一个或多个(连续的)IR版本。这些IR被称为确定性IR。
衍生IR 衍生IR是指编译器为了特定的、临时的目的而构建的IR。衍生IR可能会增强确定性IR,例如通过构建用于指令调度的依赖图。编译器可能会将代码转换进出于衍生IR以启用特定的优化。
一般来说,如果一个IR是从一个阶段传递到另一个阶段的,那么它应该被视为确定性的。如果IR是在某个阶段内部为特定目的而构建,并随后被丢弃,那么它是衍生的。
命名空间
编译器编写者还必须为IR选择一个命名空间。这个决定将确定程序中的哪些值会被暴露给优化过程。在翻译源代码的过程中,编译器必须为众多不同的值选择名称和存储位置。
图4.1具体化了这一点。在抽象语法树(ASTs)中,名称是隐式的;编译器可以通过根节点来引用任何子树。因此,(c)图中的树命名了许多在(a)图中无法被命名的值,因为其抽象层次较低。同样的效果也出现在线性代码中。(b)图中的代码仅创建了两个其他操作可以使用的值,而(d)图中的代码则创建了九个这样的值。
命名方案对优化如何改进代码有着强烈的影响。在图(d)中,t0是b的运行时地址,t4是c的运行时地址,t8是a的运行时地址。如果附近的代码引用了这些位置中的任何一个,优化应该识别出相同的引用并重用已计算的值(见第8.4.1节)。如果编译器将名称to重新用于另一个值,那么b的计算地址将会丢失,因为它将无法被命名。
使用过少的名称可能会削弱优化的效果。使用过多的名称则可能会膨胀一些编译时的数据结构,并在没有好处的情况下增加编译时间。
实际考虑因素
实际上,生成和操作中间表示(IR)的成本应该引起我们的关注,因为这些成本直接影响编译器的速度。 不同IR的数据空间需求变化范围很大。由于编译器通常会访问它分配的所有空间,数据空间通常与运行时间有直接关系。 最后但同样重要的是,我们应当考虑IR的表达能力———即IR容纳编译器所需记录的所有信息的能力。一个过程的IR可能包括定义它的代码、静态分析的结果、来自先前执行的轮廓数据以及让调试器理解代码及其数据的地图。所有这些信息都应该以一种能够清晰表达它们与IR中特定点关系的方式来呈现。