内存中值的放置
在编译器可以将源程序翻译成其中间表示(IR)形式之前,编译器必须理解代码中计算的每个值将存放的位置。编译器不必枚举所有的值及其位置,但它必须有一个机制,在翻译过程中一致且逐步地做出这些决定。通常,编译器编写者会做出一系列决定,然后在整个翻译过程中应用这些决定。这些规则合起来构成了编译代码的内存模型。
内存模型有助于定义计算的基本模型:一个操作在哪里找到它的参数?它们在确定编译器必须解决哪些问题以及需要多少空间和时间来解决问题方面起着关键作用
Memory-to-Memory Model 内存到内存模型:值的主要存放位置在内存中。 要么中间表示(IR)支持内存到内存的操作,要么代码将活跃值移动到寄存器中,并将不活跃的值移回内存。
Register-to-Register Model 寄存器到寄存器模型:只要可能,值就被保存在一个虚拟寄存器中;一些局部的、标量值仅存在于虚拟寄存器中。全局值则存放在内存中(见第4.7.2节)。
Stack Model 堆栈模型:值的主要存放位置在内存中。编译器通过显式的操作(例如,压栈push和弹栈pop)将活跃值移到堆栈上或从堆栈上移除。基于堆栈的中间表示(IR)和指令集架构(ISA)通常包括用于重新排序堆栈的操作(例如,交换swap)。
 上图展示了在每种模型下相同的加法操作。(a)显示了在两种不同假设下的操作。左列假设加法采用内存操作数,表示为符号标签。右列假设加法是寄存器到寄存器的操作,而值则存储在内存中。这两种设计之间的选择可能取决于目标机器的指令集架构(ISA)。(b)在一个寄存器到寄存器的模型中展示了相同的加法操作。它假设a、b和c都是明确的标量值,分别位于虚拟寄存器vra、vrb和vrc中。(c)根据堆栈模型展示了操作;它假设变量的主要存放位置在内存中,并由符号标签命名。
上图展示了在每种模型下相同的加法操作。(a)显示了在两种不同假设下的操作。左列假设加法采用内存操作数,表示为符号标签。右列假设加法是寄存器到寄存器的操作,而值则存储在内存中。这两种设计之间的选择可能取决于目标机器的指令集架构(ISA)。(b)在一个寄存器到寄存器的模型中展示了相同的加法操作。它假设a、b和c都是明确的标量值,分别位于虚拟寄存器vra、vrb和vrc中。(c)根据堆栈模型展示了操作;它假设变量的主要存放位置在内存中,并由符号标签命名。
这些不同的内存模型对中间表示(IR)代码的形式以及优化器和后端的优先事项有着强烈的影响。
- 在内存到内存模型中,未优化的代码形式可能只会使用少数几个寄存器。这种情况使得将值提升到未使用的寄存器中的优化变得尤为重要,尤其是在它们生命周期的非平凡部分。在后端,寄存器分配更多地关注于名称映射,而不是减少对物理寄存器的需求。
- 在寄存器到寄存器模型中,未优化的代码可能会使用比目标机器提供的多得多的虚拟寄存器。这种情况鼓励那些不会显著增加寄存器需求的优化。在后端,为了保证正确性需要进行寄存器分配,并且这是决定运行时性能的关键因素之一。
- 在堆栈模型中,目标机器的结构变得至关重要。如果指令集架构(ISA)具有堆栈操作,如JAVA虚拟机那样,那么优化的重点就放在改进堆栈计算上。如果ISA是CISC或RISC处理器,那么编译器很可能会将堆栈机代码翻译成其他形式以用于代码生成。
将值保存在寄存器中
采用寄存器到寄存器的内存模型时,编译器会尝试将尽可能多的值分配给虚拟寄存器。这种方法非常依赖于寄存器分配器,以将IR中的虚拟寄存器映射到最终代码中的物理寄存器,并将任何无法保留在物理寄存器中的虚拟寄存器溢出到内存。 编译器不能在一个赋值操作过程中将一个含糊的值保持在寄存器中。对于一个明确的值x,编译器确切地知道x的值在何处变化:即在对x进行赋值时。因此,编译器可以安全地生成将x保持在寄存器中的代码。
然而,对于一个含糊的值x,对另一个含糊值y的赋值可能会改变x的值。如果编译器试图在对y进行赋值的过程中将x保持在一个寄存器中,该寄存器可能不会被更新为新的值。更糟糕的是,在给定的过程里,x和y在某些调用中可能指向相同的存储位置,在其他调用中则不然。这种情况使得编译器难以生成正确的代码来保持x在寄存器中。将x 移交到内存可以让寻址硬件决定哪些赋值应该改变x,哪些不应该。
实际上,编译器会决定哪些值它们认为是明确的,并将所有含糊的值 移交g 到内存中的存储——数据区域之一或堆,而不是寄存器中。含糊性可以以多种方式出现。存储在基于指针的变量中的值通常是含糊的。传引用参数可以是含糊的。许多编译器将数组元素值视为含糊的,因为编译器无法判断两个引用,比如A[i, j] 和 A[m, n] 是否能指代同一个元素。
为数据区域分配值
数据区域(data region),内存中设置的一个区域,用于保存数据值。 每个数据区域都与某个特定的作用域相关联。例子包括可执行文件中的局部数据区域和全局数据区域。
对于在源程序中声明的变量,编译器会根据其个别属性为其分配一个永久的存储位置:即其生命周期、可见性和声明作用域。
- 生命周期:一个值的生命周期指的是其值可以被定义或引用的时间段。在值的生命周期之外,它是未定义的。
- 可见区域:如果一个值可以被命名——也就是说,代码可以读取或写入该值,那么这个值就是可见的。它的可见区域简单来说就是它可以被访问的代码部分。
- 声明作用域:变量的生命周期和可见性取决于声明它的作用域。例如,在C语言中,文件静态变量的生命周期是整个执行期间;它只在其声明的文件内部可见。
从存储布局的角度来看,编译器会将生命周期归类为以下三个类别之一。
自动(Automatic):一个自动变量的生命周期与其作用域(过程或块)的一次激活相匹配。该值在作用域内定义和使用,并且在退出作用域时其值就不再存在。本地变量通常默认是自动的。 我们称这些变量为“自动”,因为它们的分配和释放可以作为进入和退出相应作用域的一部分来处理。在运行时,每次调用一个过程都有自己的局部数据区域,用于存储自动变量。
静态(Static):静态变量的生命周期可能会跨越其声明作用域的多次激活。如果它被赋值,那么该值在控制权离开赋值发生的作用域后仍然保持。
编译器可以在执行前一次性分配这样的变量;实际上,它们始终存在。静态变量存储在与声明作用域关联的预分配数据区域中。编译器可能会合并多个作用域的静态数据区域。
常量值是一个特例;它们是可以通过汇编级别的指令初始化的静态值。编译器通常为它们创建一个单独的数据区域,这个区域常常被称为常量池。
规则(Irregular):一个其生命周期依赖于显式分配以及要么显式要么隐式释放的实体被称为不规则实体。 不规则变量的生命周期并不与任何单一的作用域绑定。这类变量通常是显式分配的;它可以被显式或隐式地释放。例如,在
编译器可以根据每个值的生命周期和作用域对其进行分类。这种分类建议了用于存储值的具体数据区域。下图显示了一个编译器可能使用的典型方案,用于将变量放置到寄存器和数据区域中。 给定从值到数据区域的映射后,编译器必须为每个驻留在内存中的值分配一个位置。它遍历数据区域,并在数据区域内遍历该数据区域的值。它为每个值分配一个从数据区域开始的具体偏移量 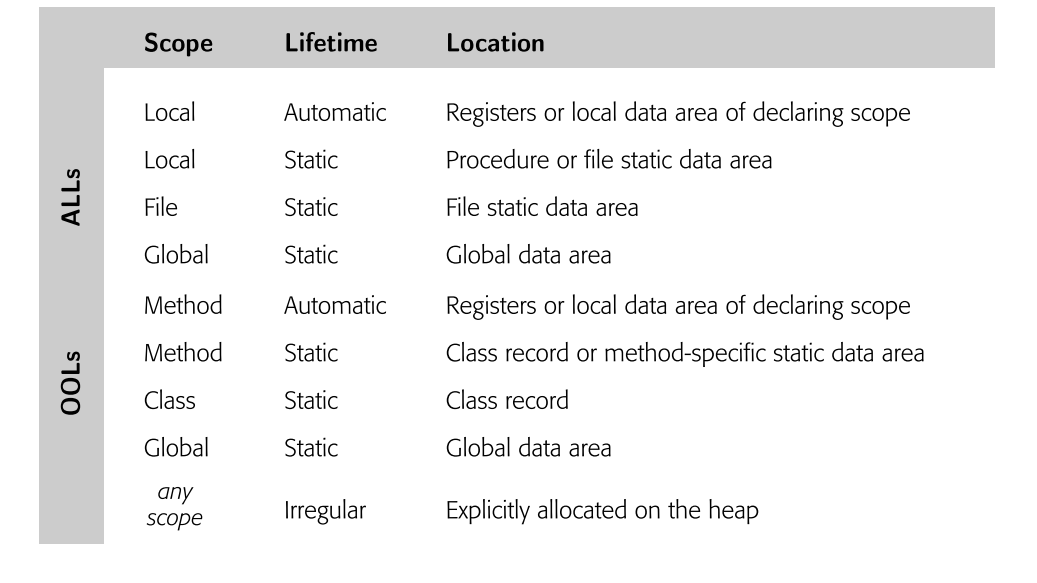
编译器必须确定程序计算的每个值在运行时将存储在哪里。编译器根据编程语言、编译器采用的内存模型、值的生命周期信息以及编译器编写者对目标机器系统架构的了解来决定这些位置。 编译器系统地将每个值分配给寄存器或数据区域,并为数据区域内的各个值分配偏移量。 关于值放置位置的决策可能会影响编译代码的性能。存储布局可以改变程序的局部性行为。存储分配决策可以编码有关底层代码属性的微妙知识,例如值的不确定性。